数据科学本科生论文被ACML 2025录用,提出KWSMOTE方法解决数据不平衡问题
近日,北师香港浸会大学(北师港浸大)数据科学专业李文杰、王瀚嶙、朱思博同学的论文《Kernel-Based Enhanced Oversampling Method for Imbalanced Classification》被人工智能与机器学习领域的知名会议—第17届亚洲机器学习会议(The 17th Asian Conference on Machine Learning, ACML 2025) 录用为conference track regular paper,指导老师为北师港浸大理工科技学院统计与数据科学系数据科学专业黎志健助理教授。
会议介绍
Asian Conference on Machine Learning(ACML)是亚太地区极具影响力的国际学术会议之一,自2009年创办以来,已逐渐发展成为机器学习领域重要的国际交流平台。会议关注范围涵盖机器学习的理论基础、核心算法、应用实践以及跨学科探索,覆盖监督学习、无监督学习、强化学习、图神经网络、生成模型、大规模预训练模型与可解释人工智能等多个研究方向。凭借严格的学术评审与高水平的论文质量,ACML每年吸引来自全球的专家学者投稿与参会,成为展示前沿成果和促进合作的重要舞台。2025年第17届ACML将于12月9日至12日在中国台湾台北举行,届时将邀请多位国际知名学者作特邀报告,并举办多场专题研讨和学术交流活动。录用的论文代表了该领域的最新研究进展,也反映出人工智能与产业结合发展的前沿趋势。
论文内容介绍
该论文提出了一种名为 KWSMOTE(Kernel-Weighted SMOTE) 的新型过采样方法,旨在解决分类任务中数据不平衡的挑战。传统SMOTE方法在生成合成样本时存在边界模糊和样本线性分布局限,而KWSMOTE通过引入核函数加权机制与局部凸组合生成策略,有效提升了合成样本的真实性与代表性。KWSMOTE的核心创新包括:
核加权机制:利用高斯核函数为近邻样本分配权重,使生成样本更集中于少数类中心区域,避免边界模糊;
凸组合生成:在局部k近邻球内生成样本,确保合成点位于原始样本的凸包内,增强几何合理性;
噪声鲁棒性:通过权重阈值跳过噪声样本,提升生成样本的纯净度与分类器性能。
该模型在五个真实世界数据集(包括医疗诊断与金融欺诈检测等)上进行了系统验证,实验结果表明,KWSMOTE在F1分数、G-mean和AUC等多个评估指标上均显著优于现有主流过采样方法,尤其在高度不平衡的数据集(如信用卡欺诈数据)上表现突出。
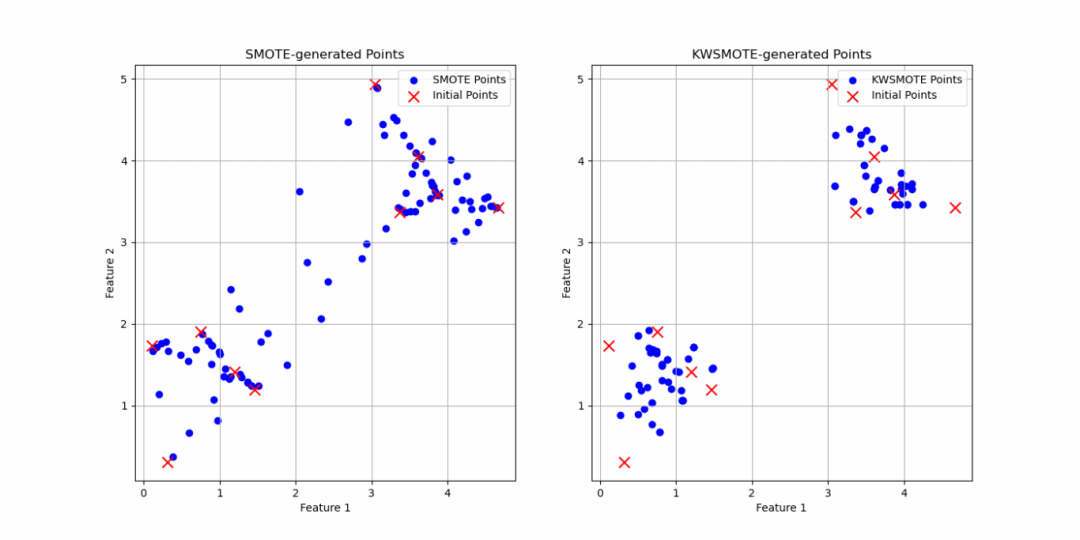
论文所提出的KWSMOTE生成点与传统方法对比示意图
审稿人评价
审稿人与领域主席对论文工作给予高度评价,认为KWSMOTE方法在理论与实验层面均做出显著贡献:其创新的核加权机制与凸组合策略,从根本上解决了传统SMOTE方法长期存在的边界模糊与样本分布不合理问题;论文实验设计严谨,在 rebuttal 阶段进一步补充大规模数据验证,结果充分体现方法的有效性与泛化能力;该研究为不平衡分类任务提供了一种高效可靠、具备理论保证且易于实现的过采样解决方案,在金融风控、医疗诊断等实际场景中展现出广阔的应用前景,为相关领域的发展提供了重要推动。

论文作者李文杰(左一)、黎志健助理教授(左二)、答辩老师陈东龙副教授(右三)、王瀚嶙(右二)、朱思博(右一)
近年来,数据科学专业多名本科生科研论文在国际会议期刊发表,不仅是对学生个人学习能力的肯定,也体现了统计与数据科学系对本科生科研水平提升做出的长期努力与投入,彰显了理工科技学院在人工智能算法改进方面科研水平的提升。
来源 | 统计与数据科学系
